About
I spend most of my time thinking about how to build robots that can understand and interact with the physical world. Currently working on world models and foundation models for robotics at Meta FAIR.
My research focuses on representation learning, 3D vision-language grounding, and cross-embodiment transfer. I'm particularly interested in how we can get robots to learn from diverse data sources and generalize across different embodiments and tasks without extensive task-specific training.
Before this, I led AI development at deep dive and studied Applied Mathematics at ITAM in Mexico City.
Background
Senior Research Engineer
World models for robotics, 3D vision-language grounding for robotic manipulation, and physical world modeling
AI Resident
Visual representations for robot control, language models for planning, and embodied AI research
Tech Lead (AI)
Computer Vision and Natural Language Processing systems
BSc Applied Mathematics
Graduated with highest honors (Magna Cum Laude), top 3% of students
Featured Publications
World Modeling
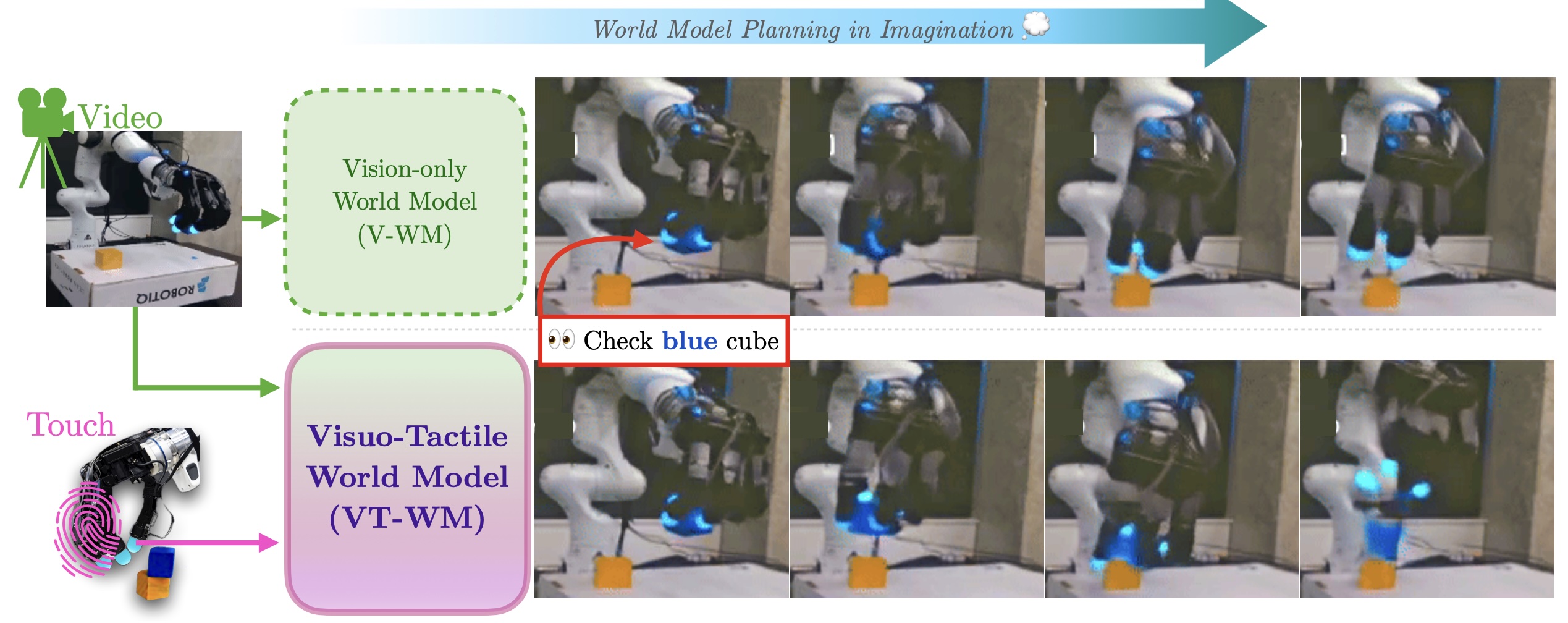
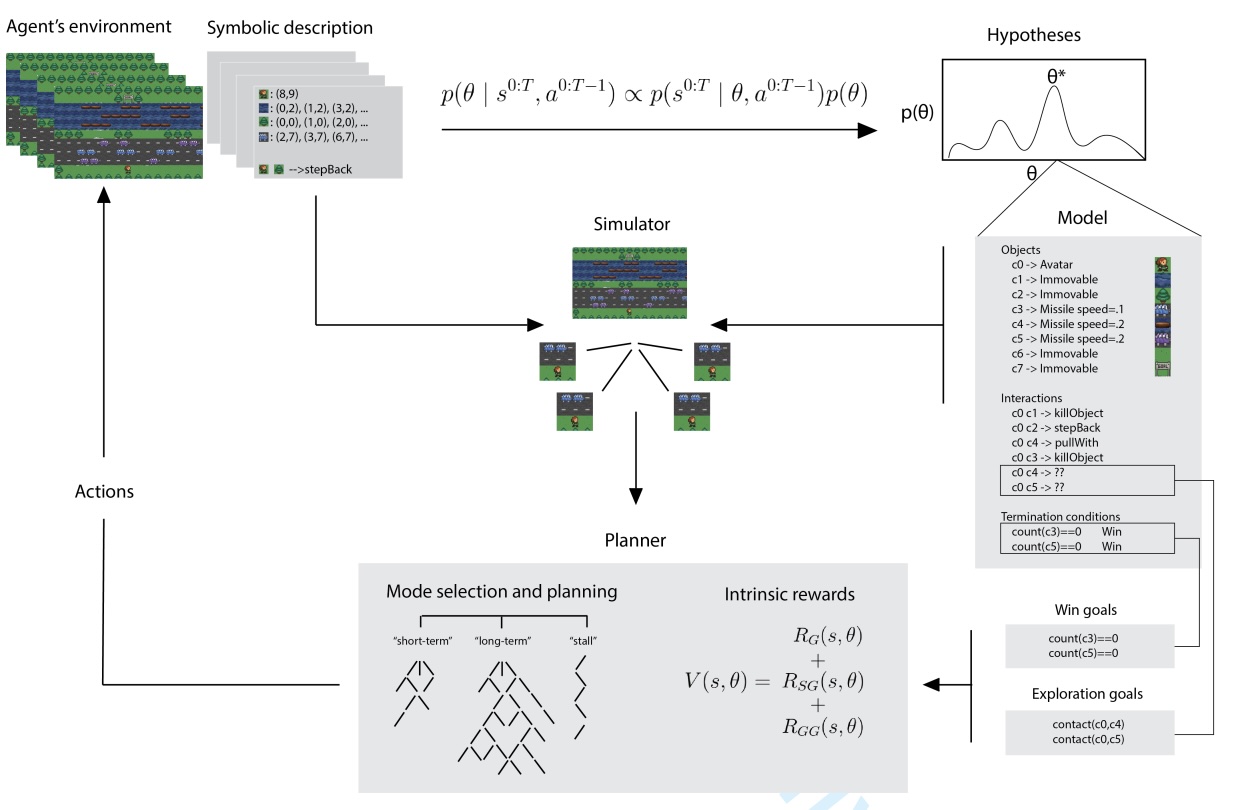
Learning predictive models of the world for planning and decision making
3D Vision & Spatial Reasoning
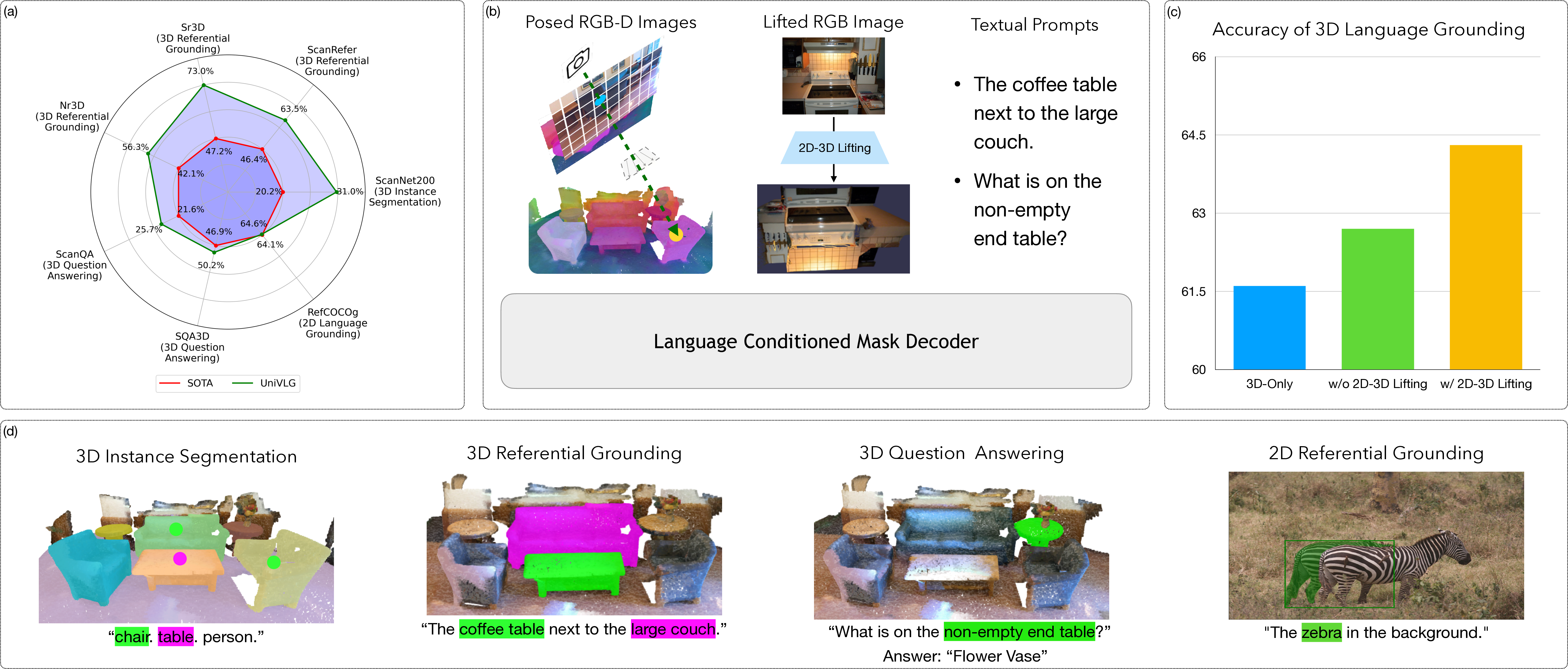
Grounding language in 3D space for embodied understanding
Representation Learning for Robotics
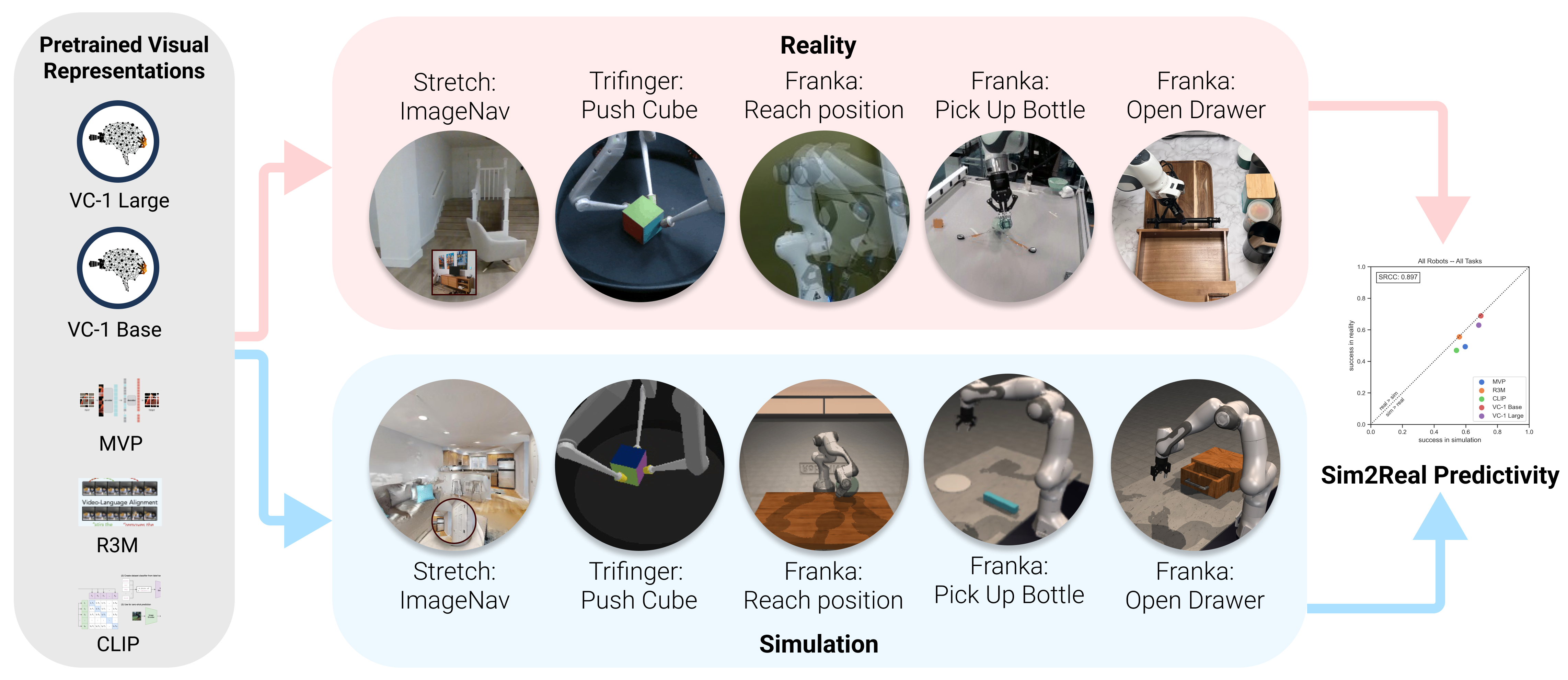
Learning visual representations that transfer across embodiments and tasks