Sergio Arnaud

About
I work on multimodal models that learn predictive representations of the physical world — how machines build internal models that support prediction, planning, and generalization. I'm currently on the World Models team at Waymo, and previously spent ~3 years as an AI researcher at Meta FAIR.
My work spans self-supervised video representation learning, 3D vision-language grounding, and large-scale multimodal training. I'm increasingly interested in interpretability — understanding what these predictive models actually learn internally.
Before research, I led the AI efforts at deep dive and majored in Applied Mathematics.
Background
Senior ML Engineer
World models and multimodal foundation models for autonomous driving
Senior Research Engineer
World models for robotics, 3D vision-language grounding for robotic manipulation, and physical world modeling
AI Resident
Visual representations for robot control, language models for planning, and embodied AI research
Tech Lead (AI)
Computer Vision and Natural Language Processing systems
BSc Applied Mathematics
Graduated with highest honors (Magna Cum Laude), top 3% of students
Featured Publications
World Modeling
Learning predictive models of the world for planning and decision making
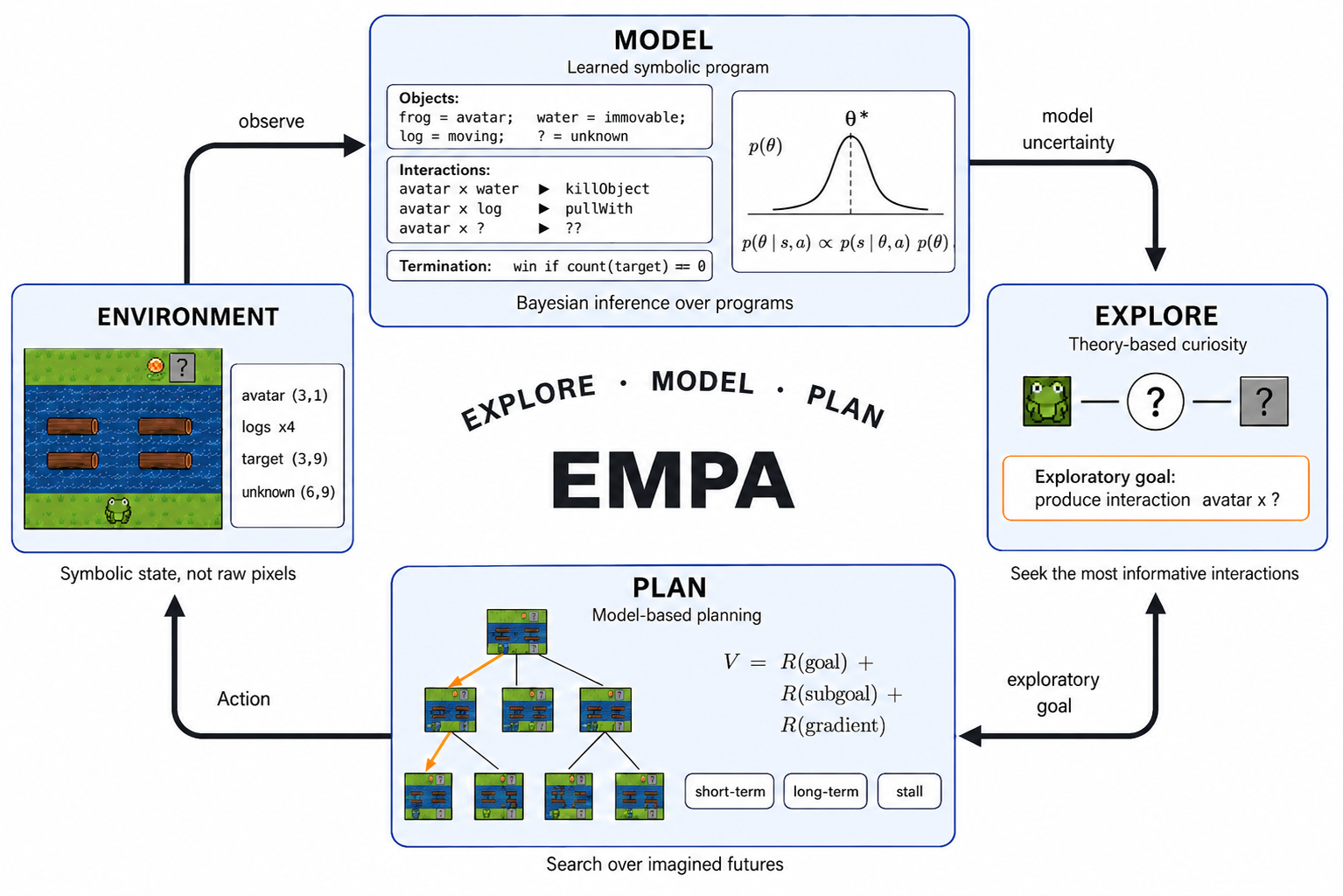
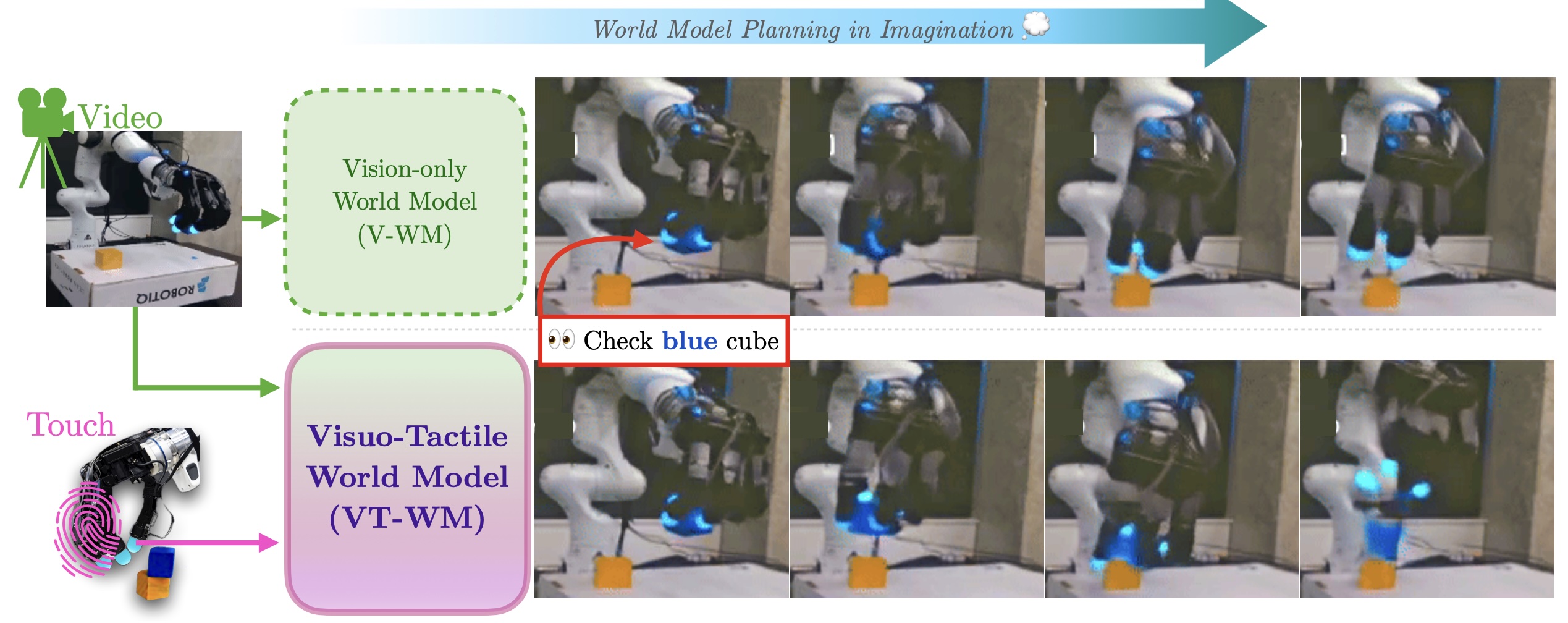
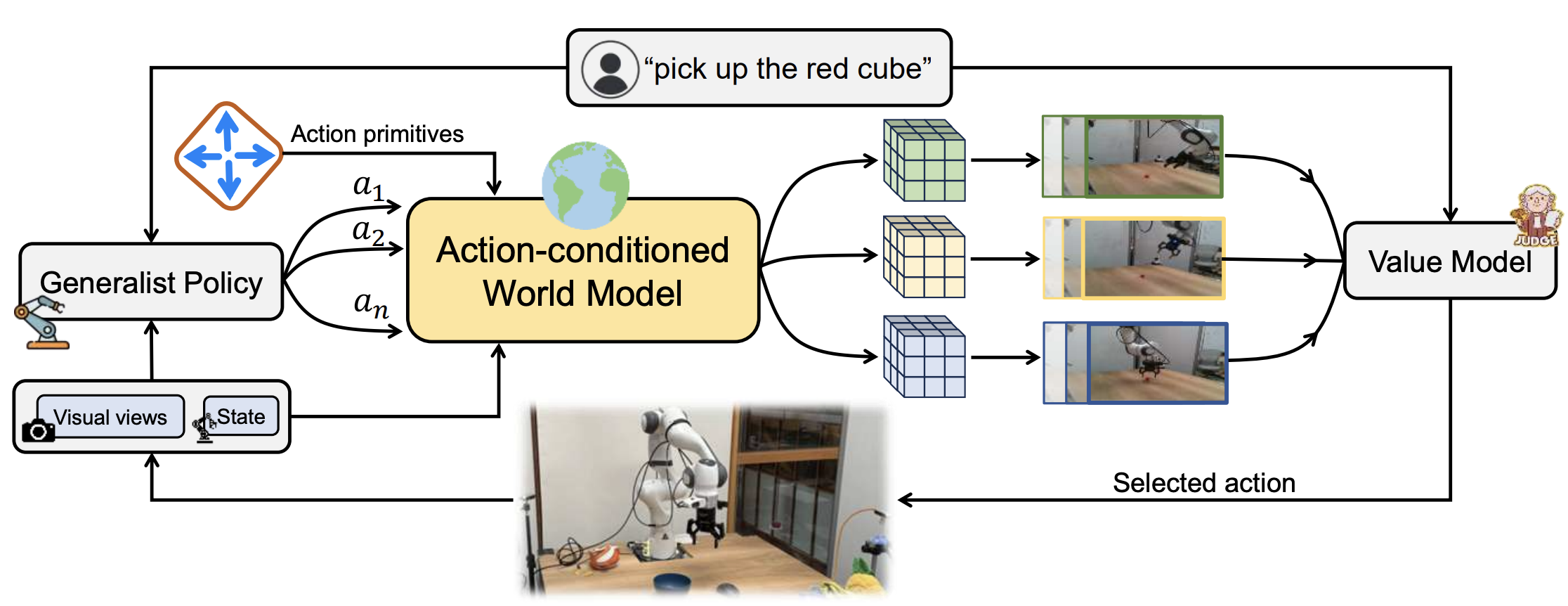
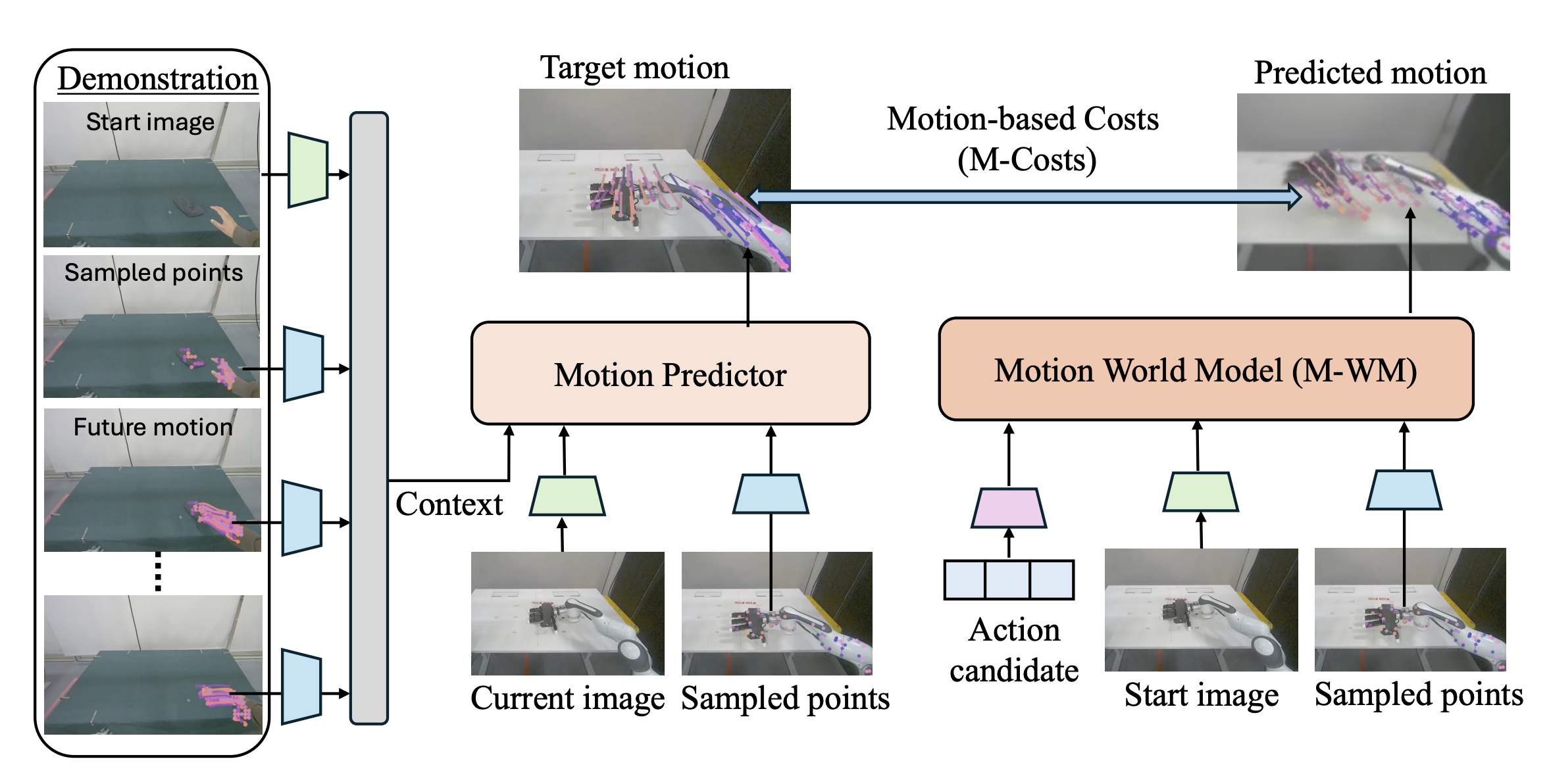
Beyond Latents: Planning with Motion Cues in World Models
Heterogeneous World Models for Cross-Embodiment Transfer
3D Vision & Spatial Reasoning
Grounding language in 3D space for embodied understanding
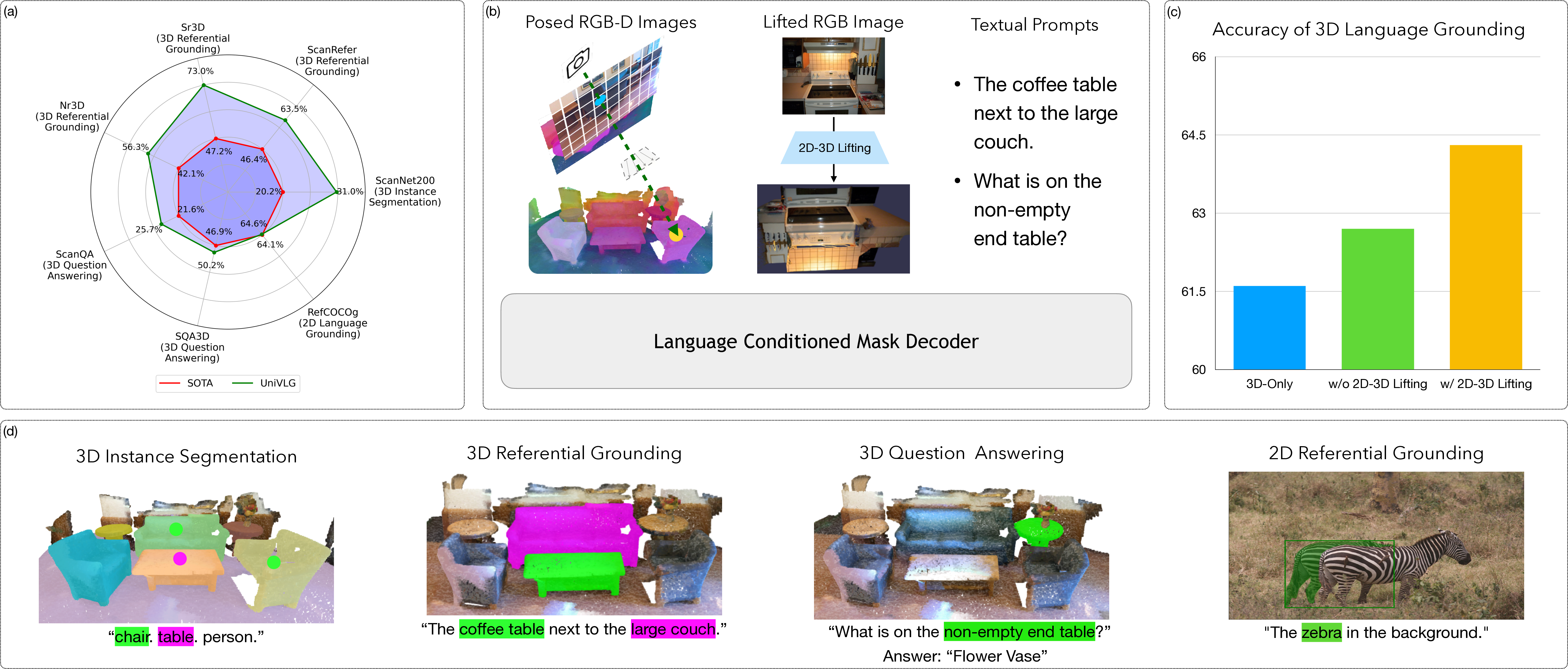
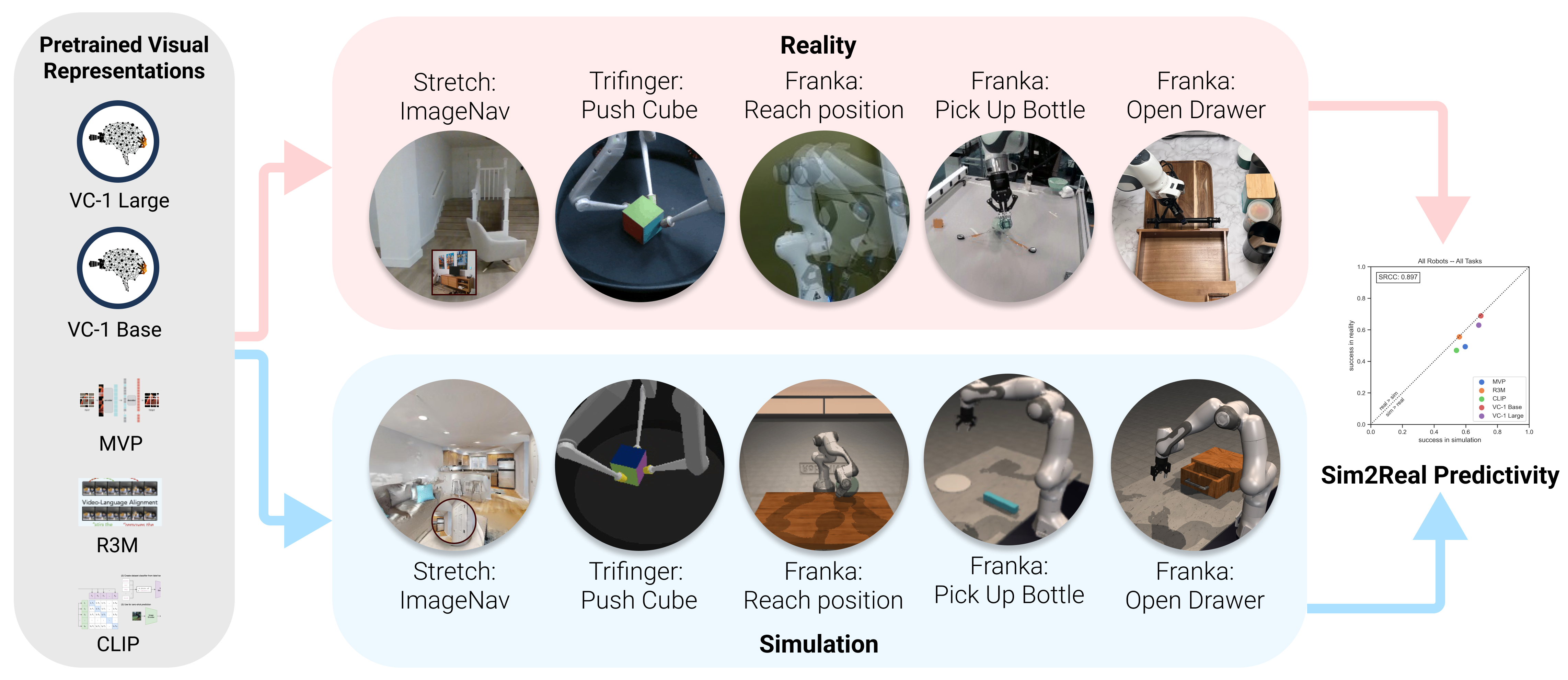
Representation Learning
Learning visual representations that transfer across embodiments and tasks
Robot Planning & Skill Coordination
Enabling robots to chain skills and plan complex behaviors